

Компания Google представила новую версию VP8 Codec SDK (libvpx 0.9.7), в рамках которого подготовлено четвёртое обновление свободного видеокодека VP8, доступное под кодовым именем "Cayuga". Формат кодирования и связанные с VP8 и WebM спецификации не изменились, изменению подверглись только средства разработки и библиотека с реализацией кодека. Следуя традиции в новой версии продолжена работа по увеличению эффективности кодирования, ускорению работы кодировщика и увеличению качества кодирования видео.
Ключевые изменения:
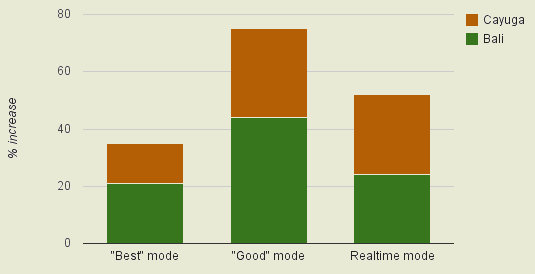
- Проведены дополнительные оптимизации скорости кодирования видео. По сравнению с прошлым выпуском скорость кодирования в режиме максимального качества (режим "Best") на x86-процессорах увеличилась на 11.5%, в режиме хорошего качества (режим "Good") на 21.5%, в режиме кодирования в реальном времени (режим "Real-time") на 22.5%. Если сравнивать производительность с самым первым выпуском libvpx, то скорость кодирования для режимов "Best", "Good" и "Real-time" возросла на 35%, 75% и 52%;
- Проведена оптимизация работы кодировщика для платформы ARM. На процессорах ARM Cortex A9 с поддержкой расширений Neon, кодирование видеопотока в режиме реального времени ускорено на 35% для одноядерных CPU и на 48% для многоядерных. На платформе NVidia Tegra2 кодирование в режиме реального времени ускорено на 40%;
- Улучшен контроль интенсивности результирующего потока (удержание битрейта в определенных рамках) при использовании однопроходного сжатия в режиме реального времени;
- При однопроходном кодировании потока в режиме с переменным битрейтом (VBR) визуальное качество картинки увеличилось в среднем на 7% при тестировании работы кодека на большой коллекции видеоматериалов;
- Улучшены характеристики кодека, связанные с использованием для обеспечения работы видеоконференций. Реализован метод сглаживания ошибок (error concealment), позволяющий обеспечить высокое качество видео, несмотря на возникновение большой потери пакетов.
- Улучшена поддержка аппаратных механизмов кодирования и декодирования видео, присутствующих в процессорах ARM v6 и v7, благодаря более плотному задействованию SIMD-расширений и использованию техники предварительной подкачки данных в кэш процессора (cache prefetching).



