

Иван Ворас (Ivan Voras), один из коммитеров FreeBSD, анонсировал новую систему для организации кэширования данных в оперативной памяти c хранением данных в формате ключ/значение - Bullet Cache. По своим возможностям и выполняемым задачам система очень близка к Memcached, отличаясь главным образом внутренней архитектурой, нацеленной на более активное использование многопоточности. Кроме того, в Bullet Cache реализовано несколько расширенных режимов для обращения к данным и определения их времени жизни в кэше, позволяющих предоставить приложению более полный контроль над хранимыми в кэше данными.
Код распространяется под лицензией BSD (2-clause BSDL). Клиентские библиотеки пока доступны только для языков Си, Python и PHP. Разработка Bullet Cache началась ещё в 2005 году, в нынешнем году интерес к проекту возродился и он был достаточно быстро доведен до стадии бета-версии, на которой он и находится в настоящее время. Изначально проект распространялся под кодовым именем mdcached (multi-domain cache daemon), но в конечном счете для избежания путаницы имя было заменено на Bullet Cache.
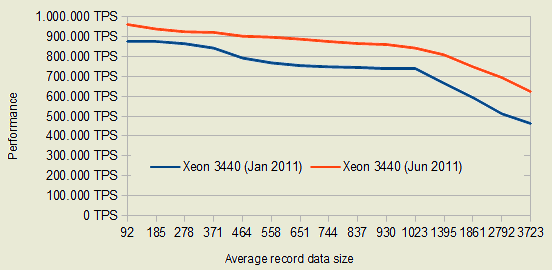
Bullet Cache изначально рассчитан на обработку большого объема параллельных запросов, что позволяет добиться заметного выигрыша в производительности на высоконагруженных серверах с многоядерными процессорами. Дополнительно отмечается использование высоко эффективных методах организации ввода/вывода и сетевого протокола, позволяющего добиться максимальной производительности при выполнении операций "GET" без лишнего копирования данных в памяти ( без вызова malloc(), realloc() и memcpy()). Тестирование производительности показало, что на обычном оборудовании (CPU Xeon 3440 2.5 GHz) миллион транзакций в секунду при смешанном выполнении операций чтения и записи в типичном для нагруженных web-проектов соотношении 90% / 10%.
Для минимизации времени на "прогрев" кэша предусмотрена возможность периодического сброса состояния кэша в файл с последующей возможностью загрузки содержимого кэша из данного файла на этапе запуска процесса. При хранении данных предусмотрена возможность привязки к записям дополнительных мета-данных, таких как теги и время жизни. Поддержка привязки тегов значительно упрощает операции группировки данных, позволяя формировать выборки запросы, охватывающие сразу несколько записей. Условия для запросов с участием тегов определяются в SQL-подобном виде, например, " GET RECORDS WHERE tag_key=... AND tag_values IN (...)" или "DELETE RECORDS WHERE tag_key=... AND tag_values IN (...)". Возможна организация таких структур, как виртуальный стек тегов (FIFO) и очередь сообщений.
В качестве ключа для идентификации отдельной записи может использовать любой набор данных (не обязательно строка), размером до 64 Кб. Максимальный размер связываемой с ключом записи - 2 Гб. Также имеется встроенная поддержка операций для добавления или удаления за один шаг больших порций данных, которые более эффективны и удобны по сравнению с перебором каждого ключа. Из дополнительных операций можно упомянуть: CMPSET для установки значения только если в записи уже определено заданное значение, FETCHADD для возвращения прошлого значения с последующим добавлением данных, READANDCLEAR для возвращения прошлого значения с последующей очисткой записи.



