После десяти месяцев разработки Увидел свет релиз распределённой БД Apache Cassandra 1.2.0, относящейся к классу noSQL-систем и рассчитанной на создание высокомасштабируемых и надёжных хранилищ огромных массивов данных, хранимых в форме ассоциативного массива (хэша). Код проекта написан на языке Java и распространяется в рамках лицензии Apache 2.0.
Изначально проект был разработан в недрах компании Facebook и в 2009 году передан под покровительство фонда Apache. Промышленные решения на базе Cassandra, способные обрабатывать тысячи запросов в секунду, развернуты для обеспечения сервисов таких компаний, как Adobe, Cisco, IBM, Disney, eBay, Netflix, Rackspace, Reddit и Twitter. Наиболее крупный кластер серверов, обслуживающих единую БД Cassandra насчитывает более 400 машин и используется для хранения более 300 Тб данных.
БД Cassandra объединяет в себе полностью распределённую hash-систему Dynamo, обеспечивающую практически линейную масштабируемость при увеличении объема данных. Cassandra использует модель хранения данных на базе семейства столбцов (ColumnFamily), отличающуюся от систем подобных memcachedb, которые хранят данные только в связке ключ/значение, возможностью организовать хранение хэшей с несколькими уровнями вложенности.
Cassandra относится к категории хранилищ повышенно устойчивых к сбоям: помещаемые в БД данные автоматически реплицируются на несколько узлов распределённой сети или даже равномерно распределяются по нескольким дата-центрам. При сбое узла, его функции на лету подхватываются другими узлами. Добавление новых узлов в кластер и обновление версии Cassandra производится на лету, без дополнительного ручного вмешательства и переконфигурирования других узлов.
Для упрощения взаимодействия с БД поддерживается язык формирования структурированных запросов CQL (Cassandra Query Language), на первый взгляд напоминающий SQL, но существенно урезанный по функциональности. Например, можно выполнять только простейшие запросы SELECT с выборкой по определённому условию, но без поддержки сортировки и группировки. Добавление и обновление данных производится через единое выражение UPDATE, операция INSERT отсутствует (если записи нет, при выполнении UPDATE она создаётся). Из возможностей можно отметить поддержку пространств имён и семейств столбцов, создание индексов через выражение "CREATE INDEX". Драйверы с поддержкой CQL подготовлены для языков Python, Java (JDBC/DBAPI2) и JavaScript (Node.js).
Из новшеств, представленных версии 1.2, можно отметить:
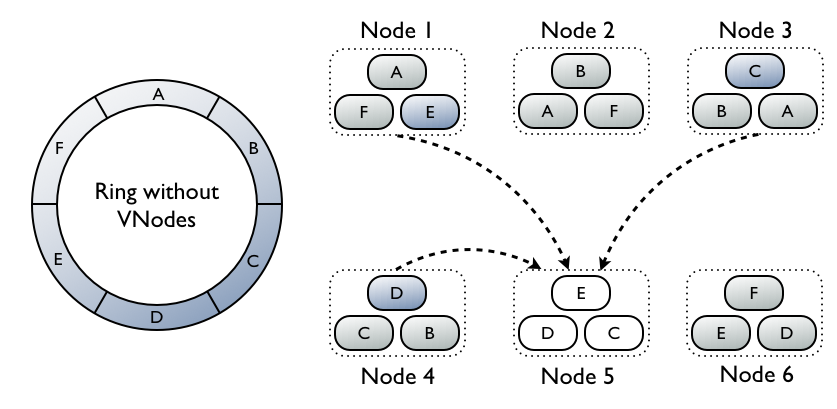
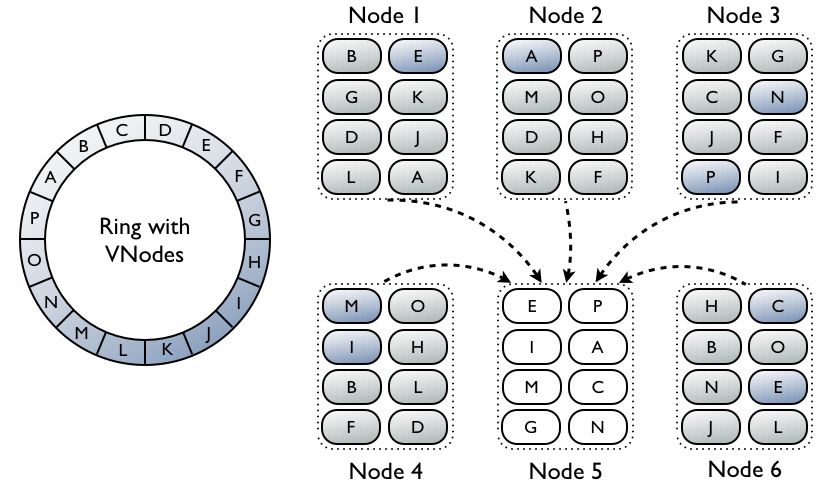
- Поддержка виртуальных узлов (vnode), изменяющих подход к привязке диапазонов данных к узлу кластера за счёт возможности представления одного физического узла как набора виртуальных узлов. Если раньше для каждого узла определялся только один диапазон хранимых данных, то сейчас к узлу могут быть привязаны несколько диапазонов. Хранения на узле независимой группы мелких диапазон, вместо одного крупного, позволяет быстрее заполнять узлы кластера, проще выводить узлы из эксплуатации, проводить восстановление и ребалансировку;
- Переход на финальную версию языка запросов CQL 3.0 (Cassandra Query Language), которая теперь используется по умолчанию. Среди новшеств CQL 3.0 можно выделить возможность использования значений нескольких столбцов в качестве первичного ключа, поддержка конструкций управления доступом (GRANT, REVOKE, LIST PERMISSIONS), расширенные функции маппинга данных;
- Поддержка выполнения пакетных операций (BATCH, аналог SQL ACID транзакций) в атомарном режиме, что позволяет гарантировать целостность крупных транзакций и обеспечить откат внесённых в рамках транзакции изменений в случае сбоя. Следует иметь в виду, что атомарные BATCH-операции выполняются примерно но 30% медленнее, поэтому для операций, требующих высокой скорости, следует использовать конструкцию без ведения лога изменений - "BEGIN UNLOGGED BATCH";
- Поддержка трассировки запросов, что позволяет контролировать как именно запросы выполняются в БД. Для включения рассировки следует использовать команду "tracing on", после чего для каждого запроса будет выведен подробный план его выполнения;
- Серия оптимизаций производительности: собственное управление размещением внутренних структур в памяти вне кучи JVM, увеличение параллелизма сохранения изменений, асинхронная доставка данных в процессе репликации, новый методом партицирования Murmur3Partitioner, увеличение производительности индексов столбцов, сериализация коллекций в бинарном виде (вместо JSON) и т.д.
- Новый бинарный протокол для CQL3, поддерживающий асинхронные соединения, подписку на уведомления со стороны сервера и передачу данных в сжатом виде;
- Расширенные опции конфигурации: отдельные варианты опции rpc_timeout_in_ms для чтения, записи, единичных и групповых операций; опция client_encryption_options для управления шифрованием; опция cross_node_timeout для защиты от перегрузки;
- Поддержка обработки сбоя отдельного диска без остановки всего узла.