Компания Searchdaimon объявила об открытии исходных текстов своего поискового движка, ориентированного на организацию работы корпоративной поисковой системы, индексирующей как данные на web-ресурсах компании, так и информацию из внутренних систем, таких как базы данных и хранилища документов.
Код открыт под лицензией GPLv2 и насчитывает около 100 тысяч строк кода на языках Си и Perl . В качестве платформы для дальнейшей разработки системы будет использоваться GitHub. После перехода на открытую модель разработки компания намерена обеспечить получение прибыли за счёт оказание консалтинговых услуг и оказание технической поддержки, а также через продажу аппаратных решений и облачных сервисов на базе поискового движка. Некоторые из компонентов из-за наличия сторонней интеллектуальной собственности открыть не удалось, например, к таким компонентам относится модуль для преобразования DWG-файлов и распределённый механизм индексации.
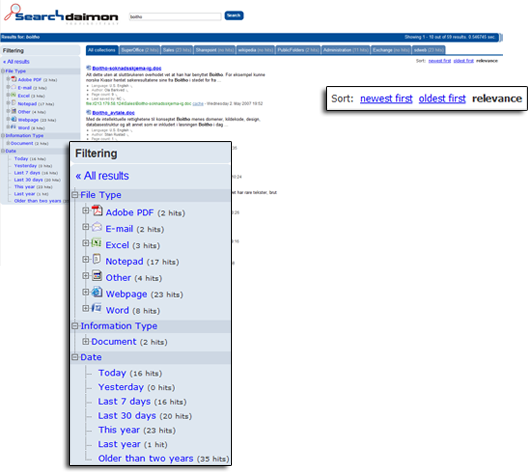
Ориентация системы на поиск корпоративной информации отразилась в наличии расширенных функций фильтрации и сортировки контента, удовлетворяющего поисковому запросу. Например, можно фильтровать вывод по формату документов, типу информации, делать выборки за определённые промежутки времени, объединять данные в коллекции. Кроме вывода в соответствии с коэффициентом релевантности предусмотрены возможности прямой и обратной сортировки по дате. При выводе результатов возможно отображение разобранных структурированных данных без необходимости обращения к источнику данных. Searchdaimon также поддерживает такие типичные для современных поисковых систем возможности, как корректировка ошибок в поисковом запросе и автоматическое предложение близких вариантов запроса (Suggest).
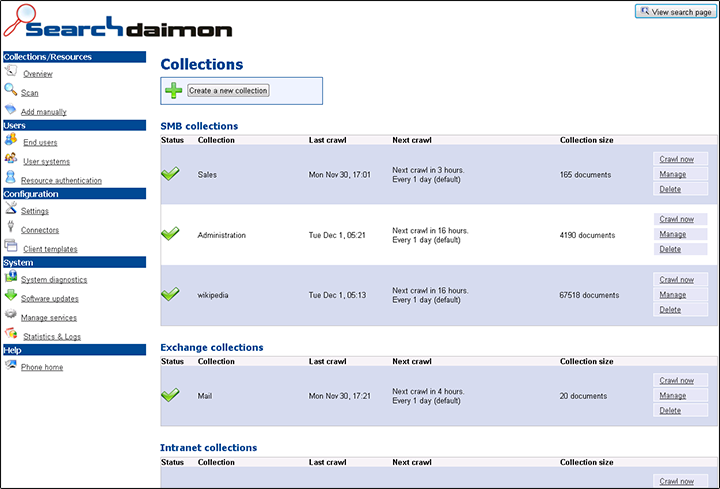
Управление системой производится через web-интерфейс администратора, через которых доступны функции добавления и удаления источников данных, управления коллекциями (SMB, Exchange и т.п.), анализа статистики (популярные запросы, активные пользователи) и просмотра логов. В качестве источников для индексации могут выступать web-сайты, документы в файловых хранизлищах (Word, PDF, Excel), SQL-базы, SharePoint, Exchange и т.п. Индексаторы дополнительных типов данных подключаются в форме плагинов.