
Оголошення оптимізованих AI-моделей для Ubuntu
23 жовтня ми оголосили про бета-версію оптимізованих для кремнію AI-моделей в Ubuntu. Розробники можуть локально встановлювати DeepSeek R1 та Qwen 2.5 VL командою, щоб отримати максимальну продуктивність апаратного забезпечення та автоматизоване управління залежностями.
Розробники застосунків можуть отримувати доступ до локального API квантизованої генеруючої AI (GenAI) моделі з оптимізаціями часу виконання для ефективної роботи на їхньому CPU, GPU або NPU.
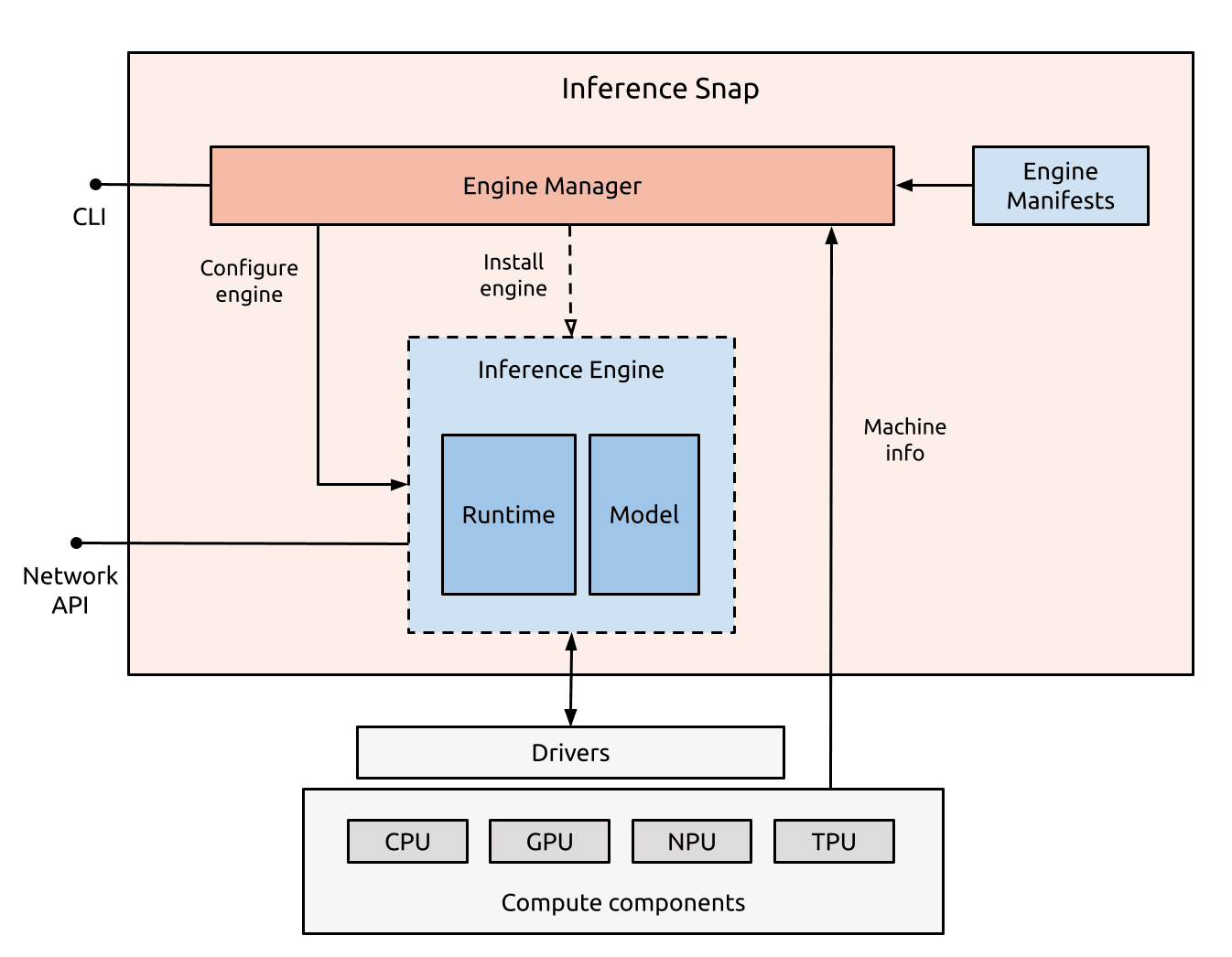
Архітектура нового інструменту з відкритим вихідним кодом, який дозволяє розробникам зібрати різні комбінації середовищ виконання та ваг в єдину snap, розгортаючи найоптимальніший стек на хост-машині.
Зустрічаючи розробників на перетині кремнію та GenAI моделей, ми пакуємо, розподіляємо та керуємо усіма необхідними компонентами для роботи AI додатків на будь-якій машині, що працює на Ubuntu. Розробники можуть тепер встановлювати попередньо навчені та налаштовані AI моделі, які автоматично виявляють підведені вимоги до кремнію, включаючи пам’ять, необхідні GPU чи NPU, а також компоненти програмного забезпечення та конфігурації за замовчуванням.
Яка візія стоїть за оголошенням, і як ми це реалізували?
Ubuntu: стандартна платформу для AI моделей
Нашою метою є зробити Ubuntu стандартною платформою дистрибуції для генеруючих AI моделей. Це дозволить розробникам seamlessly інтегрувати AI в свої застосунки та запускати їх оптимально на робочих столах, сервери та крайні пристрої.
Ми вважаємо, що навантаження з машинного навчання (ML) стане настільки ж важливим для обчислювальних платформ, як традиційні залежності програмного забезпечення сьогодні, а генеруючі AI моделі стануть базовою частиною обчислювального досвіду.
Але почекайте: хіба це вже не так? Хіба AI моделі не повсюдні, і хіба ми всі не взаємодіємо з LLM приблизно 25 разів на день?
Так, але тут є ключове уточнення. Дозвольте мені використати аналогію, щоб проілюструвати це.
Від фрагментації до кураторських архівів програмного забезпечення
У ранні дні Linux, розподіл програмного забезпечення був фрагментованим і обтяжливим. Розробники були зобов’язані вручну завантажувати, компілювати й налаштовувати вихідний код із окремих проектів, часто вирішуючи проблеми з відсутніми бібліотеками, конфліктами версій і підтримкою складного середовища складання вручну.

У 90-х роках, коли програмне забезпечення розподілялося за допомогою дискети, Slackware і Debian Linux незабаром впровадили систему кураторських архівів програмного забезпечення, що зазвичай попередньо компілювалися для економії часу.
Оскільки кожен дистрибутив мав свої власні традиції, інструменти пакування та репозиторії, встановлення програмного забезпечення було схильним до помилок і займало dużo часу. Відсутність єдиного механізму доставки гальмувала розвиток з відкритим вихідним кодом і створювала бар’єри для його впровадження.

У жовтні 2004 року було випущено перший реліз Ubuntu. Він постачався з досить фіксованим набором пакетів у архіві Ubuntu, для яких користувачі отримували оновлення безпеки та виправлення помилок через інтернет. Щоб отримати нове програмне забезпечення, розробники все ще мали відшукувати вихідний код і компілювати його самостійно.
Що змінилося?
Прискорившись на кілька років, у 2007 році Canonical представила Особисті пакункові архіви (PPA), надаючи розробникам хостинговий сервіс для публікації та обміну своїм програмним забезпеченням. Виявляти нове програмне забезпечення на Linux все ще було важко, від невідомих PPA до репозиторіїв GitHub з щоденними збірками всіх видів нового програмного забезпечення. Для виправлення цієї ситуації Canonical пізніше представила snap, контейнеризовані пакети програмного забезпечення, які спростили доставку між дистрибуціями, оновлення та безпеку.
Стоючи на плечах гігантів і побудувавши на Debian, Ubuntu допомогла змінити цей досвід, ставши точкою агрегації для програмного забезпечення з відкритим кодом (OSS). Ubuntu консолідувала тисячі проєктів на upstream у цілісну, надійну екосистему, на яку могли покладатися розробники, не потребуючи розуміти кожну залежність чи ланцюг складання, що стоїть за цим. Ubuntu допомогла уніфікувати та оптимізувати екосистему з відкритим кодом.
Сильна основа пакування, у поєднанні з стабільним темпом випусків і кураторськими репозиторіями, знизила бар’єр для розробників і підприємств. Ubuntu стала стандартним, надійним слоєм для розподілу та підтримки програмного забезпечення з відкритим кодом.
Що якби ми могли зробити те ж саме з AI моделями?
GenAI моделі як основні будівельні блоки майбутніх обчислень
Сьогодні програмні пакети є основними будівельними блоками обчислень. Розробник регулярно встановлює пакети, додає PPA та отримує від різних постачальників, третіх осіб або спільноти, не замислюючись над цим.
Ми вважаємо, що AI моделі незабаром займуть таку ж позицію, як основні компоненти в обчислювальному стеку. Вони будуть розглядатися як стандартні системні компоненти, встановлюються, оновлюються та оптимізуються так само, як і будь-яка інша залежність. Ми більше не будемо турбуватися про деталі, як управляти залежностями різних AI моделей, так само, як не замислюємося над тим, з яких репозиторіїв походять пакети, на які залежить ваш проект. Розробка програмного забезпечення природно включатиме інтеграцію ML навантажень, а моделі будуть такими ж звичними й невидимими в досвіді розробників, як традиційні пакунки сьогодні. LLM стануть частиною товарного рівня обчислень, еволюціонуючи у залежності, на які будуть покладатися контейнеризовані навантаження: комбіновані, версійовані та оптимізовані для апаратного забезпечення.
У процесі створення Ubuntu ми оволоділи мистецтвом розподілу програмного забезпечення з відкритим кодом мільйонам користувачів. Тепер ми застосовуємо цей досвід для розподілу AI моделей. Ubuntu рухається до того, щоб AI моделі стали рідним елементом обчислювального середовища. Ми переносимо AI моделі з зовнішніх інструментів в інтегральну частину стеку. Поставлення оптимізованих для кремнію AI моделей безпосередньо в Ubuntu – це перший крок до того, щоб стати вбудованим компонентом обчислювального досвіду.
Що таке моделі, оптимізовані для кремнію?
В оголошенні ми представили оптимізовані для DeepSeek R1 та Qwen VL моделі, які є провідними прикладами генеруючих AI моделей.
DeepSeek R1 – це великомасштабна модель (LLM), призначена для розбиття запитів на структуровані ланцюги мислення, що можливлює складне мислення та розв’язання проблем. Qwen VL, з іншого боку, є мультимодальною LLM, яка приймає як текст, так і зображення в якості входів, представляючи останнє покоління моделей мовного зору. Обидві базуються на трансформерах, але налаштовані та упаковані для використання різних патернів виконання та апаратних характеристик.
Давайте будемо більш специфічними. Термін модель часто використовується нечітко, але на практиці він означає цілу сім’ю моделей, побудовану навколо базової моделі. Базові моделі – це величезні нейронні мережі, навчання яких проводиться на широких наборах даних для захоплення загальних знань. Ці базові моделі часто налаштовуються, перенавчаються або адаптуються для спеціалізації на конкретних завданнях, таких як слідування інструкціям або логіка в специфічних доменах. Наприклад, трансформерні LLM мають загальну архітектуру, побудовану на компонентах, таких як самостійна увага, багатоголова увага і великі матриці впроваджень. З цієї бази можуть бути розроблені сімейства основних моделей і точно тонованих похідних, таких як моделі, настроєні на інструкції, варіанти на основі адаптерів або специфічно налаштовані моделі.
Висновок з точно тонованими моделями
Розглянемо приклад деяких моделей Mistral від Mistral AI.
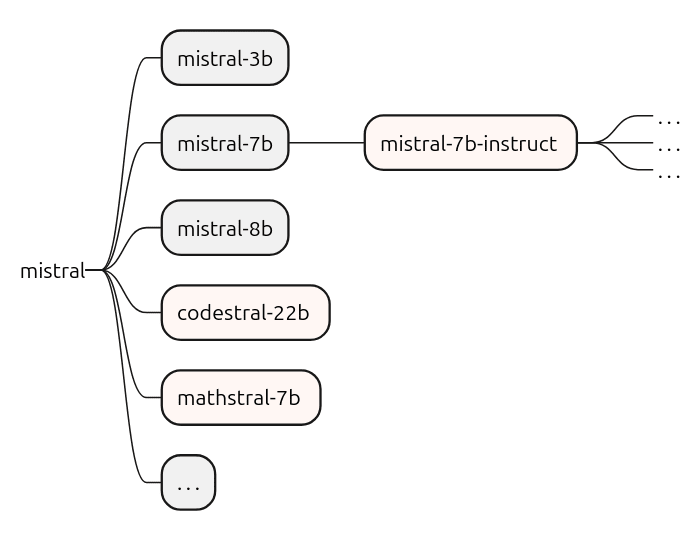
Ліворуч у нас є постачальник моделі, у даному випадку Mistral AI, який навчає та розподіляє основні базові моделі. Тоновані похідні, такі як mistral-7b-instruct, потім адаптуються для використання, заснованого на інструкціях, реагуючи на запити структуровано та в контексті.
Інша сім’я моделей може виглядати подібно, але мати на меті інші цілі чи архітектури:
Однак «модель» – незалежно від того, базова вона чи тоновані – не є особливо корисною сама по собі. Це, по суті, набір вивчених ваг: мільярди чисельних параметрів без контексту виконання. Для розробників важливий стек висновку, комбінація навченої моделі та оптимізованого середовища виконання, яке робить можливим висновок. У літературі термін «модель» часто відноситься до повного артефакту моделі, включаючи токенізатор, компоненти попередньої та постобробки, і формат виконання, наприклад, PyTorch checkpoint, ONNX та GGML.
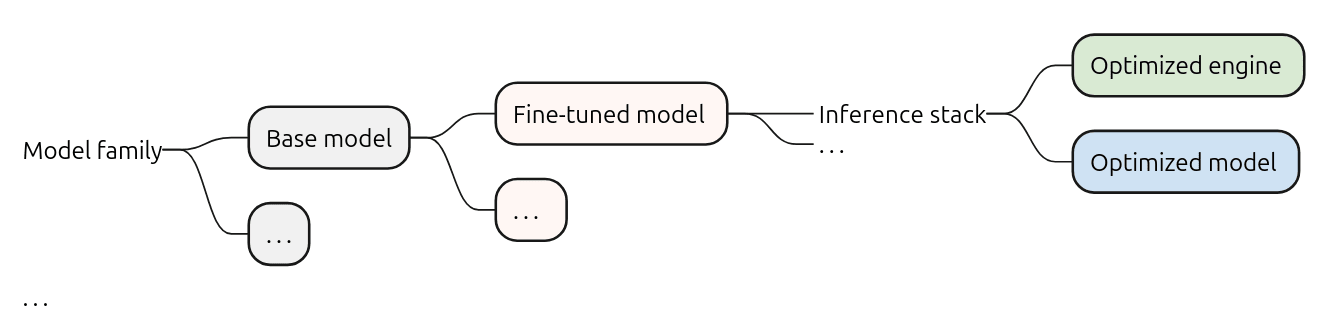
Стек висновків включає в себе механізми висновку, програмне забезпечення, відповідальне за ефективне виконання моделі на певному апаратному забезпеченні. Окрім ваги попередньо навченої моделі, наприклад, ваги Qwen 2.5 VL, квантовані за Q4_K, двигун зазвичай включатиме логіку виконання, оптимізації для ефективного виконання матричних множень та підтримуючі підсистеми. Приклади включають Nvidia TensorRT, Intel OpenVINO, Apache TVM та специфічні для постачальника середовища виконання для NPU. Для однієї й тієї ж моделі може існувати кілька стеків, кожен з яких адаптовано до різних архітектур або цілей продуктивності. Ці механізми відрізняються підтримуваними функціями, реалізаціями ядра та шарами інтеграції з апаратним забезпеченням, що відображає відмінності в можливостях CPU, GPU, NPU або прискорювачів.
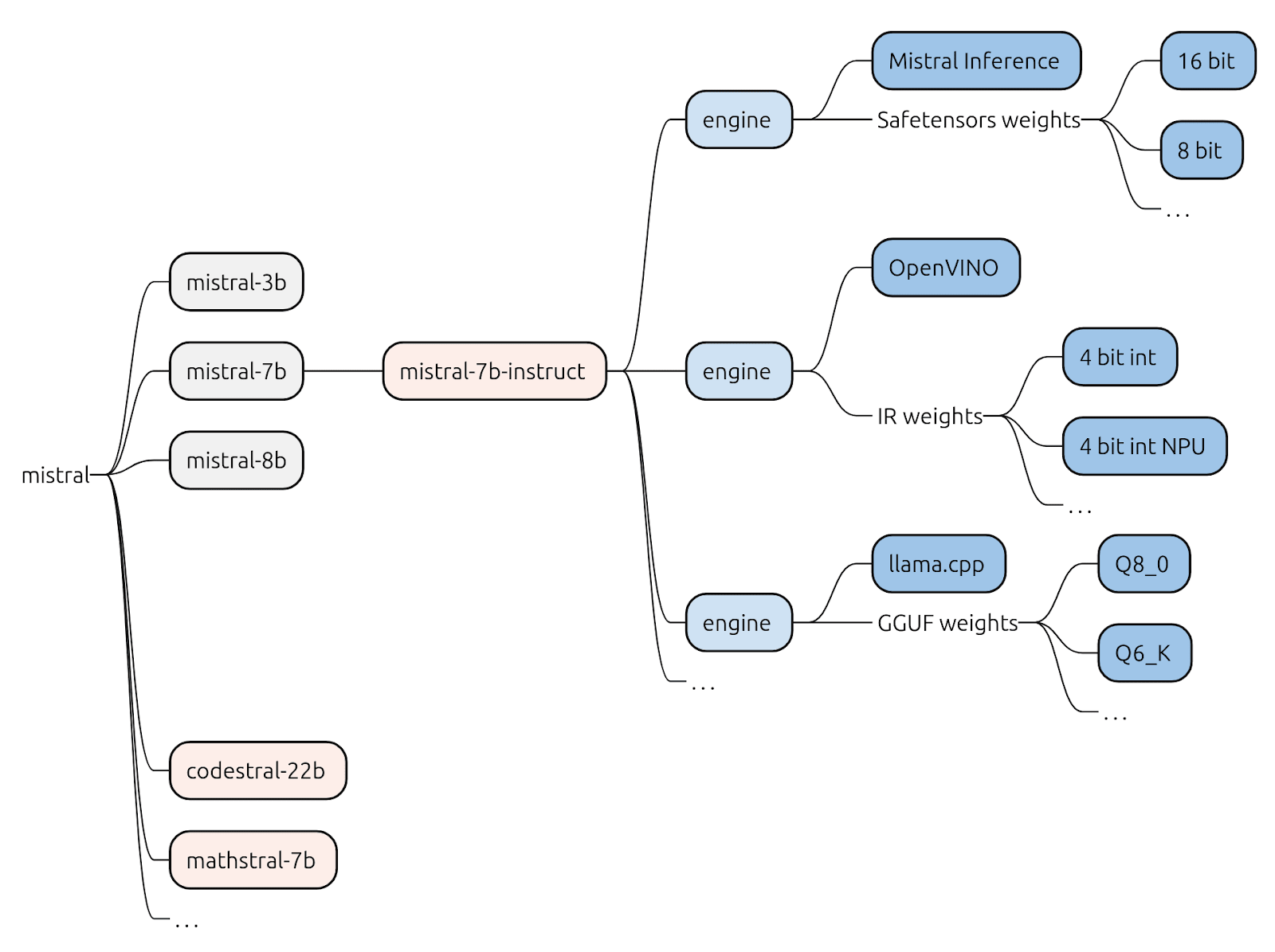
Наприклад, для тонованої моделі, як-от mistral-7b-instruct, можна знайти кілька стеків висновку:
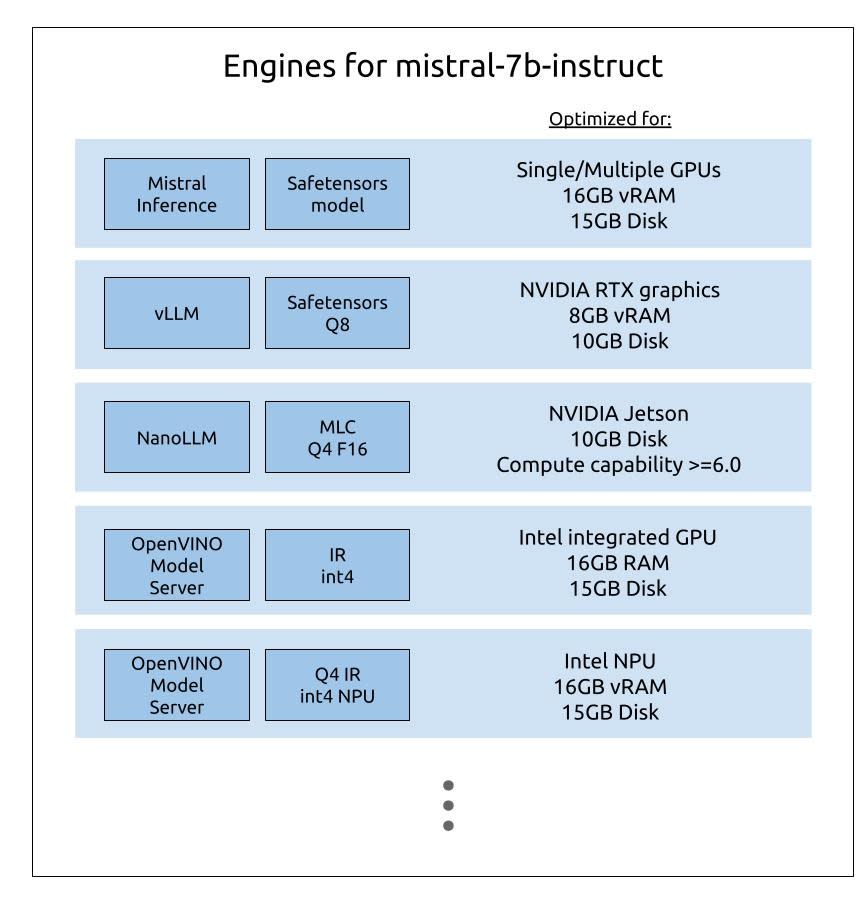
Оптимізація апаратного забезпечення для висновку
Ефективне виконання LLM критично залежить від підлеглого апаратного забезпечення та наявних системних ресурсів. Ось чому оптимізовані версії точно тонованих моделей часто є необхідними. Загальна форма оптимізації – це квантування, яке знижує числову точність параметрів моделі (наприклад, перетворення 16-бітних плаваючих точок у цілі числа 8 або 4 біти). Квантування зменшує обсяг пам’яті моделі і обчислювальне навантаження, що дозволяє швидше виконувати, або встановлювати на менших пристроях, зазвичай з мінімальним зниженням точності.
Крім квантування, оптимізація може бути специфічною для кремнію. Різні архітектури апаратного забезпечення, наприклад, GPU, TPU, NPU або спеціалізовані AI прискорювачі, мають унікальні характеристики продуктивності: щільність обчислень, пропускну здатність пам’яті та енергоефективність. Постачальники використовують ці характеристики за допомогою варіантів моделей, які оптимізовані або компілюються, щоб максимізувати продуктивність на своєму специфічному кремнію.
Для постачальників кремнію демонстрація переваг продуктивності висновку безпосередньо перетворює на ринкову диференціацію. Навіть незначні вдосконалення – 2% підвищення продуктивності або затримки на провідному LLM – можуть мати значні наслідки, коли масштабуються по дата-центрах або розгортаються на краю.
Ця гонка продуктивності живить інтенсивні інвестиції в оптимізацію AI моделей у всій «екосистемі» апаратного забезпечення. Кожен постачальник прагне максимізувати ефективні TFLOPS та реальну ефективність висновку. В результаті формується розширюючиється ландшафт варіантів моделей, що оптимізовані для апаратного забезпечення, від агресивно квантованих моделей, що відповідають суворим обмеженням пам’яті, до версій, налаштованих для GPU, що використовують тензорні ядра та паралельні конвеєри обчислень.
Крім того, пакування моделей і формат виконання впливають на розгортання, адже потрібно оптимізовані артефакти для кожного цілі, наприклад, TorchScript/ONNX для GPU, створені постачальником виконувані для NPU, GGML або int8 CPU версії для обмежених пристроїв.
Як наслідок, розробники, які розробляють вбудовані AI застосунки, вимушені мати справу з API-ключами, підпискою на токен і застосунками, що працюють лише під час підключення до швидкого інтернету. Пакування та розподіл програмного забезпечення, що працює на AI, є важким завданням. Розробникам потрібно враховувати десятки типів кремнію, сотні конфігурацій апаратного забезпечення та все зростаючу кількість моделей і варіантів, при цьому управляючи залежностями, оновленнями моделей, середовищами виконання, API-серверами, оптимізаціями та інше.
Спрощення розробки AI: абстрагуючи складність
Чи можливо абстрагувати цю складність? Сьогодні розробники будують на Ubuntu, не думаючи про підлегле апаратне забезпечення. Той же принцип має бути застосований до AI: що якщо, у майбутньому, розробник може просто писати код для DeepSeek, не турбуючись про вибір оптимального варіанту точно тонування, вибір правильного двигуна висновку або націлювання на специфічну архітектуру кремнію?
Це виклик, який ми поставили перед собою, заповнюючи прогалину між потенціалом AI та його практичним впровадженням. Наша мета – надати розробникам правильні моделі та зробити LLM частиною повсякденної розробки програмного забезпечення.
Ми уявляємо світ, де розробники застосунків можуть націлити модель AI, а не стек, й безшовно використовувати оптимізації, специфічні для апаратного забезпечення, за лаштунками. Щоб справді скористатися потенціалом AI, розробники не повинні піклуватися про рівні квантування, середовища висновку чи приєднання API-ключів. Вони просто повинні розробляти відповідно до єдиного інтерфейсу моделі.
На жаль, сьогоднішня екосистема AI все ще роздроблена. Затури розробників не мають стандартної моделі пакування і розподілу, що робить впровадження AI дорогим, непослідовним і складним. Команди часто витрачають значний час на налаштування, бенчмаркінг та налаштування стеків висновку для різних прискорювачів, робота, яка вимагає глибокої експертизи, і все ще залишає апаратуру недоиспользованою.
Саме тому, завдяки міцному партнерству в екосистемі Canonical, ми представили абстрактний шар, який надає користувачам доступ до розробки з використанням відомої моделі, інтегруючи специфічні для апаратного забезпечення стеки. Минулого тижня ми оголосили про публічний бета-реліз AI моделей на Ubuntu 24.04 LTS, з DeepSeek R1 та Qwen 2.5 VL збірками, оптимізованими для апаратного забезпечення Intel та Ampere. Розробники можуть локально встановлювати ці snap, попередньо налаштовані для їх кремнію, без мук з залежностями або ручним налаштуванням. Наш підхід snap дозволяє розробку на основі стандартного API моделі в Ubuntu, покладаючись на оптимізовані збірки, інженерні команди Canonical, Intel та Ampere.
Оптимізації постачальників кремнію тепер будуть автоматично включені при виявленні апаратного забезпечення. Наприклад, коли ви встановлюєте snap Qwen VL на amd64 робочій станції, система автоматично вибере найпідходящий варіант – чи то оптимізований для Intel інтегрованих чи дискретних GPU, Intel NPU, Intel CPU, чи NVIDIA GPU (з CUDA-прискоренням). Аналогічно, на arm64 системах за допомогою процесорів Ampere Altra/One буде використовуватися версія, оптимізована для цих CPU. Якщо жодна з цих оптимізацій не відповідає апаратному забезпеченню, Qwen VL автоматично повернеться до загального движка CPU, щоб забезпечити сумісність.
Партнерство Canonical з кремнієм: планування на майбутнє
Як ми вже побачили, продуктивність AI моделі тісно пов’язана з кремнієвим шаром. Оптимізація для кремнію охоплює кілька рівнів, від зниженої числової точності до злиття операторів та ядер, змінитв структуру пам’яті і плитки, і конкретні реалізації ядра постачальників. Сам стек висновку, від TensorRT, ONNX Runtime, OpenVINO/oneAPI до середовищ виконання NPU постачальників, істотно впливає на затримку, пропускну здатність і використання ресурсів. Співпрацюючи з лідерами кремнію, Canonical тепер може надавати надійні, стабільні, локально оптимізовані моделі, які ефективно працюють на робочих станціях, серверах і крайніх пристроях, знижуючи залежність від масивних розгортань GPU в хмарі, зменшуючи витрати та енергоспоживання, покращуючи затримки та зберігаючи чутливі дані на пристрої. Кожну модель можна встановити одним командою без ручного налаштування або управлення залежностями. Після встановлення snap автоматично виявляє підлеглий кремній, в даний час оптимізований для Intel CPU, GPU та NPU і Ampere CPU, застосовуючи найефективнішу комбінацію вибору середовища виконання та варіанту моделі.
З Ubuntu Core, Desktop та Server ми вже надаємо послідовний досвід ОS мільйонам розробників у різних галузях та формах. Тепер ми готові продовжити наше співробітництво з кремнієвою спільнотою та більшою екосистемою й маємо чудову можливість впроваджувати AI моделі в усіх сферах обчислень.
Зв’яжіться з нами сьогодні
Цікавитесь, як запустити Ubuntu у вашій організації?




